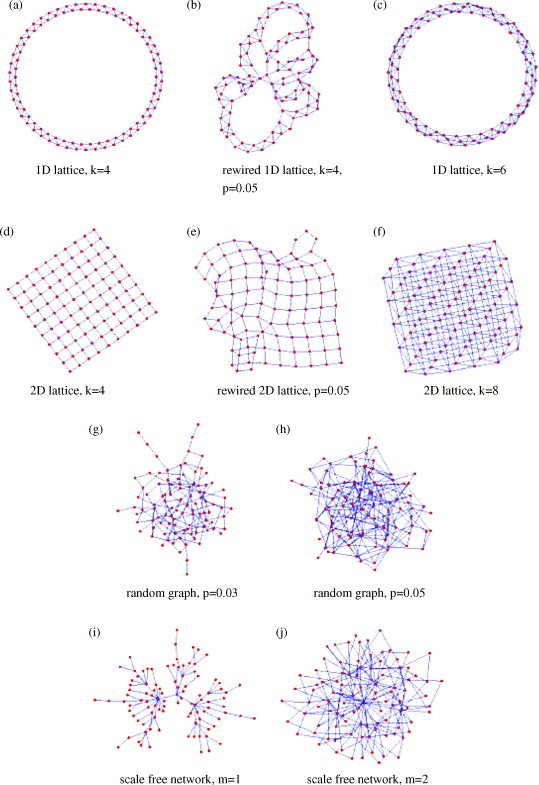
Have you ever had one guy throwing your match in that MOBA (multiplayer online battle arena) game, FPS (first person shooter), or other game? A lot of the time I certainly had this occur, and its not fun. Sometimes, when matched up with teammates of similar skill as well as opponents of similar skill, these result in the best possible matches you can have as things get super close. Zhenxing Chen, a researcher at Northeastern University, has created a matchmaking algorithm that uses familiar items we have learned in class.
The algorithm begins by taking all other players in the que and puts them into a complete graph. Each edge has what is called a “churn” rating. Essentially, this is measured by how much time has elapsed since the last matchmaking decision was made and the time elapsed before the player chose to play the game again. Players are matched by attempting to pair the minimum sum of edges.
This model focuses on maximizing player engagement, rather than on player skill like other matchmaking systems including the “Bradley-Terry” model or the “elo” model. While this may cause some more imbalance in terms of player skill for matchmaking, this model will result in more player engagement, and therefore more player retention.

But how do we measure player engagement correctly? Some factors that we can say for sure are both time spent playing and/or money spent playing the game. Additionally, as discussed above, time between sessions can also be a good factor. If a player had a very poor matchmaking experience, this makes it more likely that they will want to quit the game or take a long break from it. However, good matchmaking experiences will make players want to play more, therefore resulting in a shorter time period between matchmaking processes.
There where a few very interesting finds when experimenting with this algorithm. For the scenario of a players total wins plus the total amount of losses is greater than two times the amount of draws, then our engagement matchmaking algorithm is approximately equal to the skill based models discussed previously. However, if it is less than rather than greater than, then skill based matchmaking ends up being the worst form of matchmaking.
When testing out the engagement matchmaking algorithm, it was tested with a random sample of players between 100 to 500 in size. The matchmaking systems used were worst matchmaking, skill based matchmaking, random matchmaking, and our engagement matchmaking. The engagement matchmaking managed to have slightly higher player retention than all the other forms of matchmaking.
It is very cool to see how graphs can be used for video game matchmaking like this, especially when it is within your favorite hobby. Graphs can be very useful in the most unexpected ways!