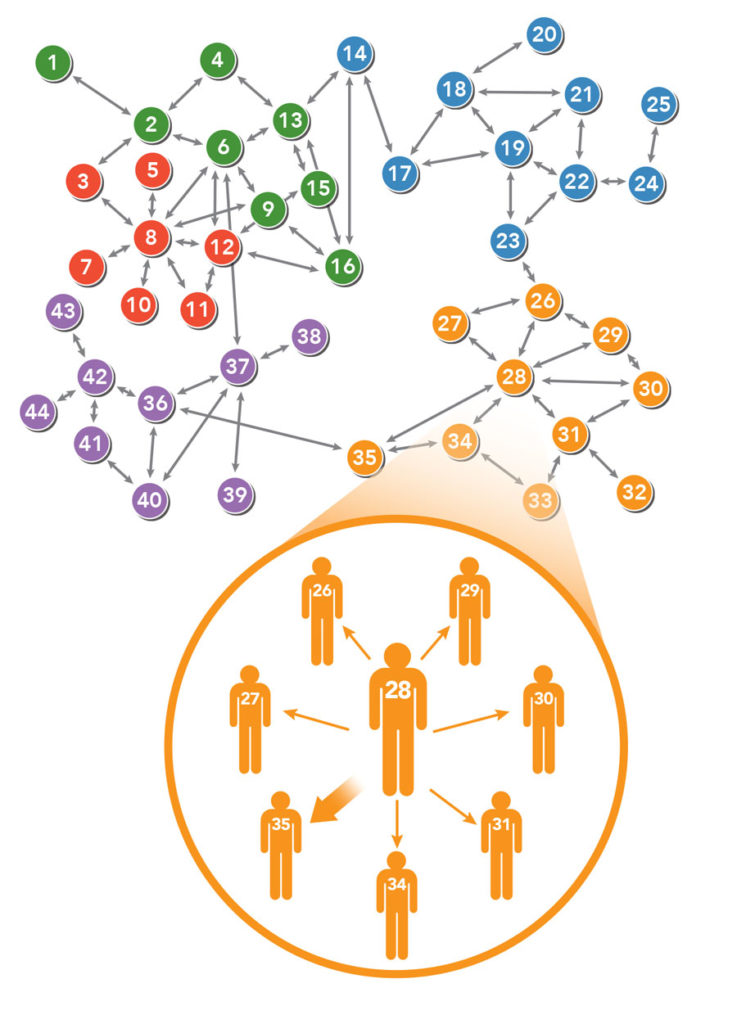
In class we learned about small worlds, clustering co-efficients, and path length. Throughout our class discussions we often used social media, and social networks as examples. But graph theory is a far-reaching field and the topics we covered in class can also be used in various other networks; including the brain function network.
In an article published in May 2019 titled “Brain Network Analysis of Schizophrenia Based on the Functional Connectivity” researchers outline how graph theory can be used to identify the effects of schizophrenia on the brain function network. In their study, the researchers analysed the Magnetoencephalography (MEG) of 9 patients with ‘normal’ brain activity and 9 patients who had been diagnosed with schizophrenia. MEG is a neuroimaging technique for mapping brain activity by recording the magnetic fields created by the electrical impulses within the brain [2]. In the introduction the authors note that, “High efficiency analysis of small world network topology has become the main way to analyze brain function network.” This is due to the high connectivity and efficiency of the human brain function network. The goal of the study was to compare the small world properties of the schizophrenic brain function network against that of the ‘normal’ brain network. This was achieved by first mapping the brain function connectivity network in a resting state with MEG. Since the brain function connectivity network can fluctuate over time, even in the resting state, the study used a sliding window technique to capture the left temporal and frontal MEG signals of the 18 patients in a resting state with their eyes closed.
The researchers then processed these signals in order to produce binary and weighted networks. From these networks they calculated the average shortest path length and the average clustering coefficient. The study found that the ‘normal’ human brain shows increased small world properties when compared to the schizophrenic brain. The healthy patients brain function networks had comparatively smaller shortest path lengths and higher clustering co-efficients. Graph theory analysis of the brain function network can produce significant results for better understanding schizophrenia, an often crippling disease. This study shows that patients with schizophrenia have decreased small world properties in their brain function networks, which may result in a slower information exchange rate and lower efficiency.
The study outlined above highlights how graph theory can be used not only to help us understand the overall structure of the social world, but also naturally occurring biological structures. The human brain is an extremely complicated organ that we do not fully understand. However, through the use of graph theory we can better understand the healthy structures and patterns that exist within our brains and how variations within those structures (such as decreased connectivity) can impact our health. Schizophrenia, among many other mental illnesses, is both poorly understood and potentially incapacitating. Knowing that graph theory can be used to provide better diagnosis and to possibly move us closer to providing assistance to those impacted by the disease highlights how deep of an impact graph theory can have, not just in understanding the world around us, but also in using that understanding to significantly help those in need.
RESOURCES:
[1] X. Zhang, L. Wang, Y. Ding, L. Huang and X. Cheng, “Brain Network Analysis of Schizophrenia Based on the Functional Connectivity,” in Chinese Journal of Electronics, vol. 28, no. 3, pp. 535-541, 5 2019.
doi: 10.1049/cje.2019.03.017
URL: http://ieeexplore.ieee.org.myaccess.library.utoronto.ca/stamp/stamp.jsp?tp=&arnumber=8812649&isnumber=8812608.
[2] Magnetoencephalography . In Wikipedia. Retrieved October 12, 2019, from https://en.wikipedia.org/wiki/Magnetoencephalography
[3] Brain Map: Temporal Lobes. In Queensland Health. Retrieved October 12, 2019, from https://www.health.qld.gov.au/abios/asp/btemporal_lobes