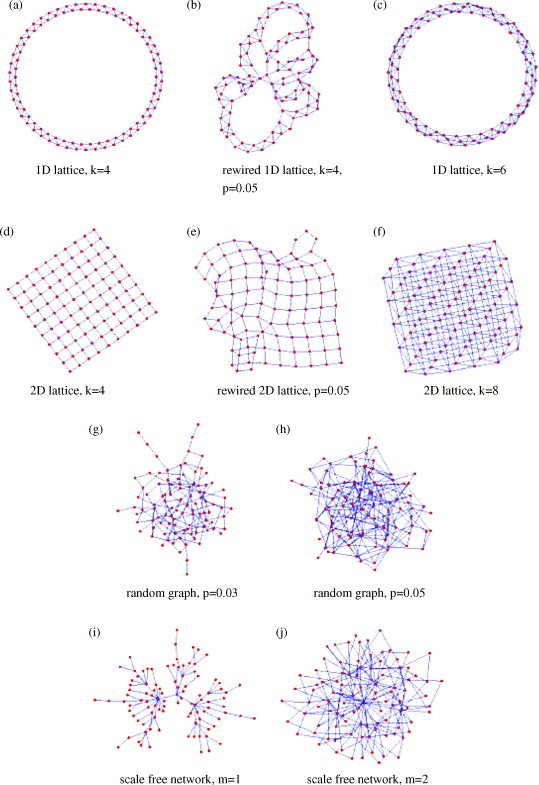
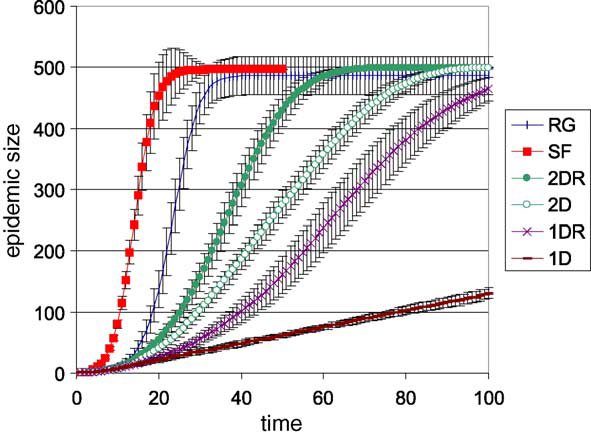
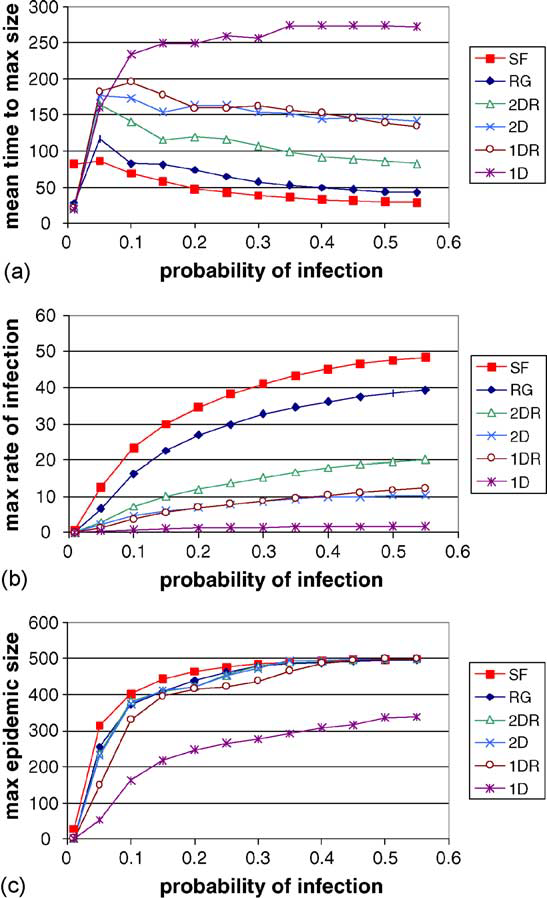
In epidemics there is the basic reproductive number R_0 is crucuial in determining if epidemics can blow up or die out. Ideally we want R_0 to be below 1 in order for the epidemic to die out. One way would be to reduce p, the probability of infection. Vaccines seem like an obvious and simple way to reduce p, however not everyone gets vaccinated. A recent study published this year called, Epidemic prevalence information on social networks can mediate emergent collective outcomes in voluntary vaccine schemes, analyzes the effect of vaccination on epidemics while using game theory.
Getting vaccinated can be viewed as a payoff matrix. Getting vaccinated requires time which many value more. On the other hand, herd immunity can still protect unvaccinated individuals at no cost as long as enough of the population is sufficiently vaccinated.As a result, many individuals may choose to not get vaccinated but still be protected by vaccines because there are less infectious people. For rational agents, it may seem disadvantagous to sacrifice time to get vaccinated when the individual still benefits from herd immunity regardless.
In the study researchers studied the dynamics of epidemic spreading and vaccine uptake behaviour on a social network containing N people. The model uses the popular SIR epidemic model with transmission rate β, and average infectious time period of τI. In the study they varied the transmission rate and average time period. One unique aspect of the model is the introduction of vaccinations, which prevents susceptible individuals from being infected, which makes them functionally similar to recovered individuals.
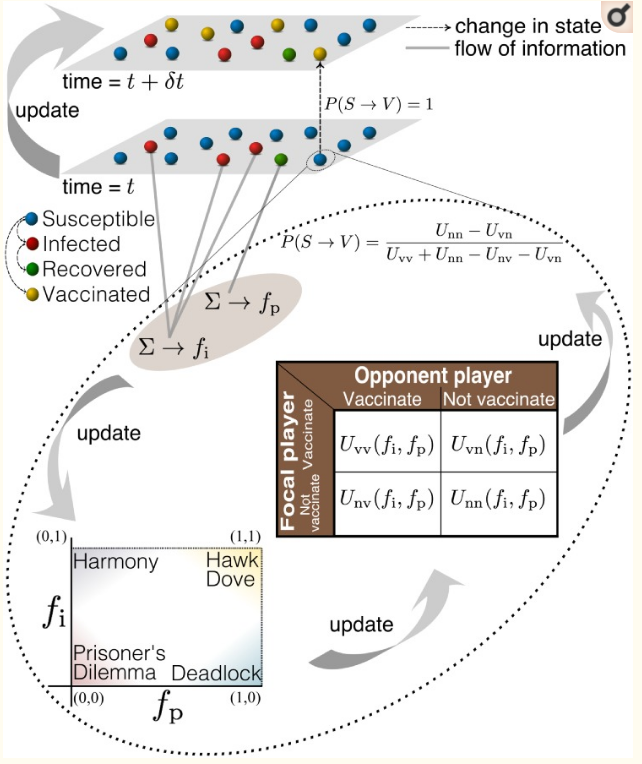
Individuals have access to local information such as number of infected cases among direct contact neighbours in the network, and global information about how prevalent the disease is across the whole network. The player’s payoff matrix evolves as time passes, since the payoffs are based on the disease prevalence, where a higher prevalence of diesease increases the payoff for getting vaccinated. Interestingly, the payoff to not vaccinate increases as the number of direct neighbours are vaccinated or immune to the disease.
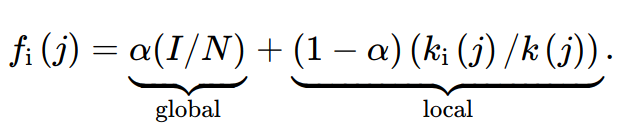
The formula for the payoff of vaccination scales based on α∈ [0, 1], which is a weight factor determining the impact of global vs local information. For example, if α=1, then individuals only considers global information on the epidemic when determing the payoff matrix for vaccinate/don’t vaccinate, but if α=0 then the individuals only consider local information.

The results of the 1000 epidemic simulations with β= 0.025 , τI = 10, and α=0 or α=1 are shown above. When α=1 people don’t initially get vaccinated, but when the epidemic becomes significantly higher then there is a mass surgence of vaccinations, akin to how media exposure only occurs when epidemics grows large which in turn can trigger vaccinations. Also, the fraction of infected, inf∞, is always higher in α=1 regardless of R_0, which is in line with the observation that people get vaccinated based on global epidemic data. This may suggest that dispersing local information about epidemics is more important than global information.
This study shows the importance of information dispersal in combatting epidemics. The results may suggest more efficient disease control by providing local information. It is also interesting to note how payoff matrices can change in relation to the environment.
Links: