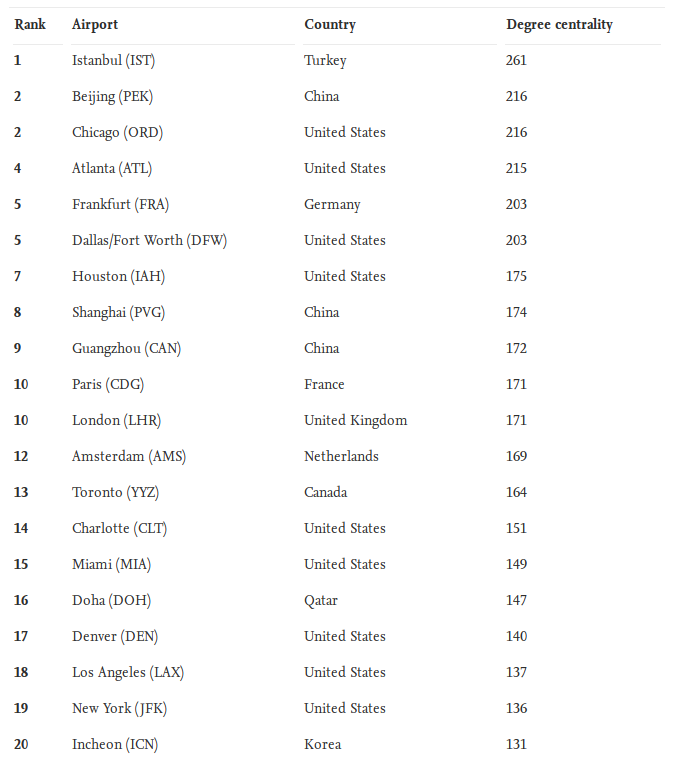
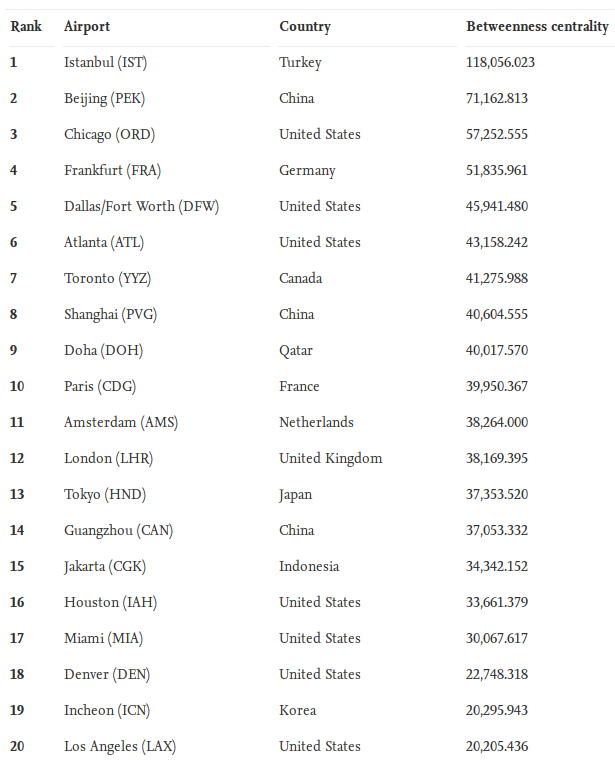
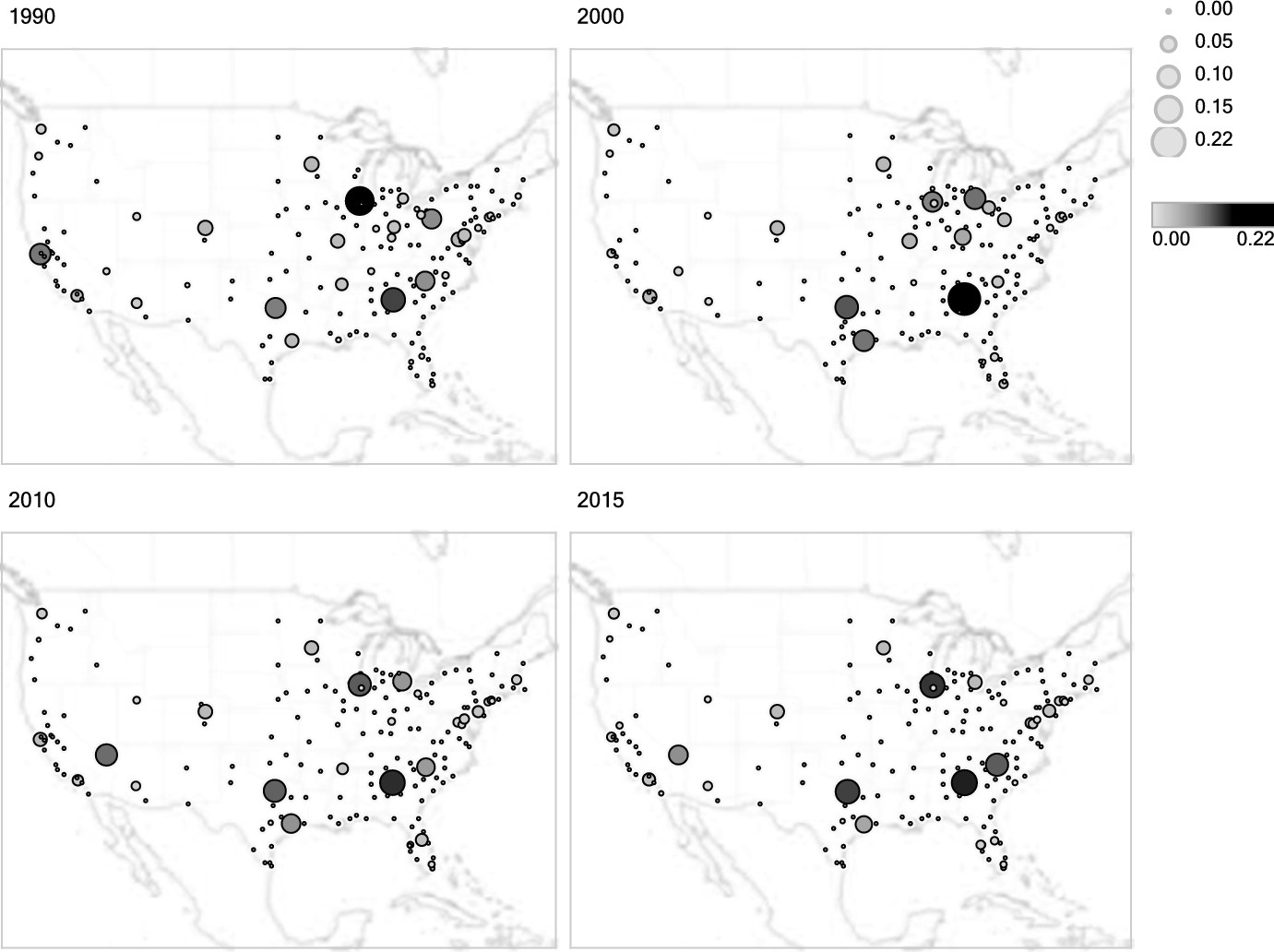
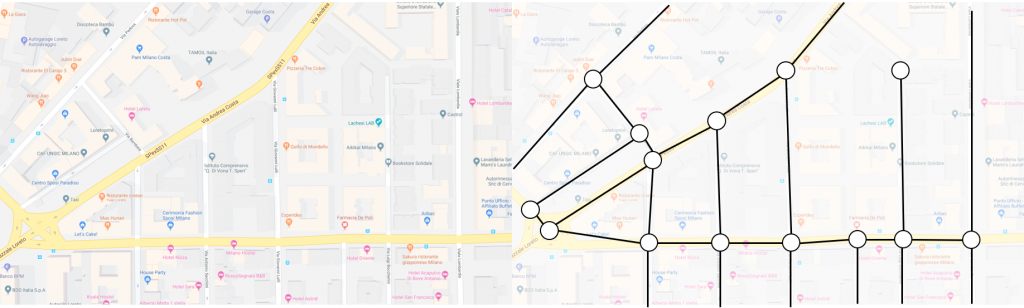
A majority of the young adults that fall within the age ranges of 18 and 30 in this day and age are all jumping on the same wagon of folks that are looking to get into a relationship — or should I say relationships (make note of the plural). With the plethora of dating apps available to the masses, people are quick to start a relationship with someone they think is a compatible match for them. These people are also quick to end it if they no longer think it’s going to work out due to “compatibility issues” that are realized a few weeks/months/years into the relationship. It is for this reason you might observe that in your own relationships (or the relationships of your friends), you tend to date people that are similar to you, which could also be the answer as to why your current partner may be similar to your ex(es). We will take a look at an article by Nicola Davis that tries to figure out the reason as to why new partners are often like exes and see homophily’s prevalence in dating.

In the article “Just my type: why new partners are often like exes,” Davis talks about how research has been done by psychologists that confirm people date others that have a personality similar to their own. This may seem like an obvious point, but it also provides some reasoning as to why an individual’s “former and new partner tend to be alike in character.” It is from the results of their study that they can not only predict who will get together with who, but also the chance of a relationship succeeding. From this, we can see how apparent homophily is when it comes to choosing a partner – people want someone that is ” interested in the same things and have the same attitudes to life ” as them. However, when the relationship fails with one partner, people might end up choosing another one that has characteristics similar to the ex. In this cycle of break-ups and hook-ups, people will always end up choosing some individual that is similar to every single one they’ve chosen before. It then follows that there is a potential that friends similar to you in personality/character got into a relationship with one of your exes, or maybe even one of your potential partners.
Finding a partner that is truly compatible with you is often a laborious task. Individuals often think their next partner will be better and different from the last when in reality, they’re most likely to be similar in some way, shape, or form. After all, birds of a feather DO flock together whether you expect it or not. This then begs the question of whether or not one should date someone that is similar to them in character. At the end of the day, if you want a relationship (whether it’s romantic or platonic) to last, it would be better if you and your partner have the same interests/attitudes on life, or else you’ll end up with incessant arguments and a broken heart.

LINKS –
https://www.theguardian.com/science/2019/jun/10/just-my-type-why-new-partners-are-often-like-exes