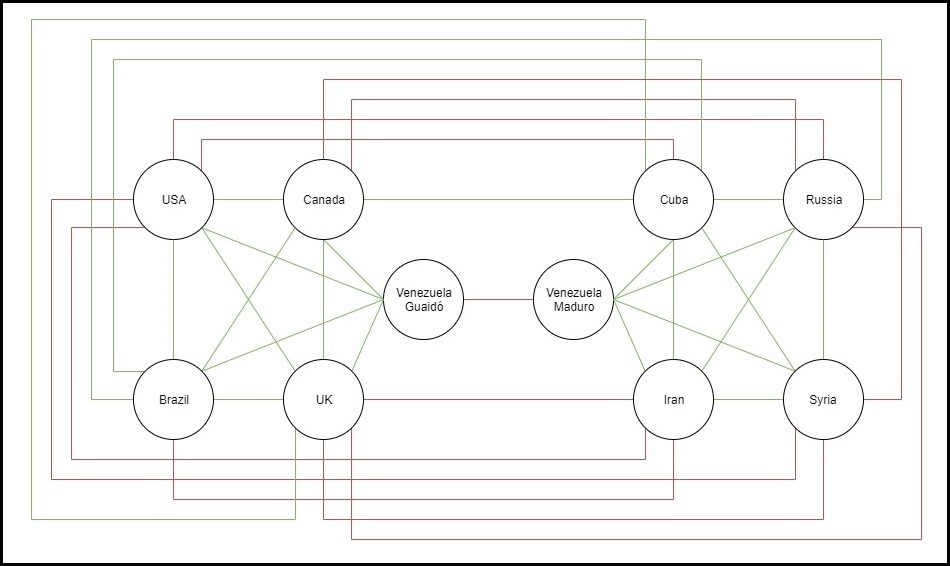
In last Monday’s class (30/09/19), we had discussed the notion of balance in graphs, following the reasoning of how relationships between friends and enemies would be structured in realistic scenarios. If you have a balanced graph, you can used known relationships to predict the relationships between nodes. For example, if you know that A is friends with B and B is enemies with C, it would be reasonable to guess that A is enemies with C as well. I thought that it would be interesting to apply this logic to a real-world situation and examine the relationships between nations. For this, I want to look at the ongoing Venezuelan Presidential Crisis. In short, the need to know is that there is a global debate regarding who is the rightful president of Venezuela between Nicolás Maduro and Juan Guaidó. Among the countries aligned with Maduro you have the likes of Russia, China, and Cuba. Of those supporting Guaidó, you would find the USA, Canada, Brazil, and the UK. Keep in mind that the full list of countries and their declared allegiances is much larger, but I just want to paint a general picture.
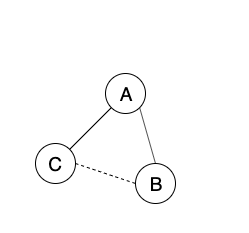
At the centre of the issue, you have the two Venezuelan parties, which can be comfortably labelled as having a negative relationship. We can also label the relationship between the Venezuelan parties and their respective supporters as being positive. This gives us two clear factions, one supporting Guaidó and the other Maduro. According to the logic dictated by balanced graphs, it would hold to reason that the countries within these factions would all have positive relations with each other and negative relations with countries in the opposing faction. This statement manages to hold in most high-profile cases, as shown in figure 1, with some examples being USA-UK or Russia-China, but there are some notable exceptions.
A prominent outlier I want to highlight is Canada-Cuba which have had very strong relations for decades. Despite this friendship, Canada and Cuba are in opposing factions regarding the Venezuelan Presidential Crisis. This Canada-Cuba relationship manages to create an unbalance in the graph, but would that strictly mean the relationship itself it prone to collapse? Over the recent months, I have not heard of any deterioration in the relationship between these two countries despite the clear difference in policy regarding Venezuela. Of course, it wouldn’t be surprising to read that there is an increase in tension behind closed doors, but as of right now, it doesn’t feel accurate to say that Canada-Cuba relations are in someway flawed. This relationship causes other issues with balance such as how Canada-Iran has a negative relationship, yet Cuba-Iran has a positive relationship.
Due to the Canada-Cuba example, I feel that it may be rather difficult to find a perfectly balanced graph using real-world data as the world is simply too intricate to be able to definitively say who are enemies and friends of whom. An important aspect to consider is that edges are binary, negative or positive. Relationships with countries are volatile and subject to change. An example is Brazil-Russia, notably in opposing factions, where their relationship has been improving, but are still in a tough position to gauge whether their current relationship could be described as friendly. Another thing to consider is a neutral relationship, such as the one between the UK and Cuba. Such a relationship couldn’t be expressed with graph balancing as each edge must be coloured as negative or positive, not allowing for neutrality of any kind. This is not to say that the notions of balanced graphs aren’t useful, but it may be more reasonable to look at an overall level of balance, such as relating to probability, as opposed to merely saying that the graph is balanced or unbalanced.
2019 Venezuelan Presidential Crisis Summary:
https://www.bbc.com/news/world-latin-america-48121148