In recent news, Elon Musk has been forced to buy Twitter after backing out of the 44-billion-dollar deal after claims that the number of bots on the platform were “wildly higher” than the 5% estimate Twitter had disclosed publicly. In fact, Musk claimed that in the past at least 20% of Twitter accounts were bots. These percentages vary widely considering that there are almost 300 million active users on the platform, which leads to the question; how were the number of bots calculated at all?
There are a wide variety of techniques used to detect bots on social media platforms such as text-based and feature-based analysis. A text-based approach entails looking for patterns in user generated content, such as specific keywords, but it can be easily circumvented with ai assisted text generation. Then there are feature-based approaches which look for patterns in numerical features such as metadata, however this can also be thwarted. This is where graph-based bot detection comes in. By analyzing the patterns of behavior in a user’s Twitter network, it is possible to detect bots with a higher degree of accuracy.
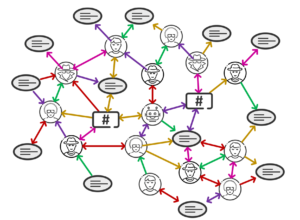
Graph-based bot detection work by interpreting users as nodes and relationships as edges. These relationships can be used to generate strong and weak ties between users by viewing not only who follows who, but also by measuring the number of interactions between users. This can be done by looking at features such as the number of times users have retweeted others or replied to tweets. By looking at the relationship between users, it is possible to see how central a user is to the Twitter network. This is important for bot detection as bots tend to have a more peripheral position in the network. This means techniques such as node centrality can then be used to detect bots more accurately.
Centrality is a measure of how important a node is in the network and there are a few different ways to measure it. One common measure is degree centrality, which is simply the number of edges a node has. In this example, a node with a high degree centrality is more connected to other nodes in the network and is therefore more important, but this may not be an accurate representation of all bots. Because bots may interact between each other at a higher degree in “bot communities”, it is important to measure centrality not only with degree, but betweenness.
Betweenness centrality – the number of shortest paths between two nodes that pass-through a given node – can give us a more accurate depiction of these bot networks. A node with a high betweenness centrality is more likely to be a bridge between different parts of the network, if these number of bridges follow a specified trend, they could potentially be weak ties that connect bot communities with the wider Twitter network. Bots tend to have a lower degree centrality because they generally follow fewer people and are followed by fewer people. They also tend to have a lower betweenness centrality because they are less likely to be a bridge between different parts of the network. These types of networks are hard to test against, and so, pre built datasets like TwiBot-22 exist to simplify this process.
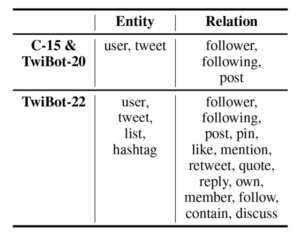
Table depicting different data used to build graph-based bot detection datasets.TwiBot-22 uses heterogeneous graph building that contains 92,932,326 nodes and 170,185,937 edges
There are a few things that are interesting or novel about this subject. Firstly, the fact that bots are becoming more sophisticated and can circumvent text-based and feature-based detection methods. This means that we need to find new ways to detect them, and graph-based bot detection is one of the most promising methods. Secondly, the fact that bots tend to have a lower degree centrality and betweenness centrality is interesting as it suggests that they are less connected to the wider Twitter network. This could be because they are part of smaller, self-contained bot communities. Finally, the fact that we can learn about these bot networks and how they operate by adopting a network science approach is extremely valuable. By understanding the patterns of behavior in these networks, we can develop better methods for detecting and combating them.
Sources:
- https://twibot22.github.io/
- https://arxiv.org/abs/2206.04564
- https://www3.nd.edu/~cone/centralities/nodecentrality.html
- https://www.businessinsider.com/elon-musk-data-scientists-didnt-find-many-bots-twitter-hid-2022-9
One reply on “Using Graph Theory for Twitter Bot Detection”
Very interesting. I did know about the massive quantities of bots Twitter had, but never expected the so called ‘bot communities’. Unfortunately, I don’t see a way to make a platform bot free as of now, although I can certainly see how this method would reduce the number of bots in twitter by a substantial amount. Anyway, good work!