Introduction
When we eat out, we will often times look for reviews online on websites ranging from just Google or perhaps Yelp and the like.
Indeed, Yelp being one of the largest platforms for reviews means that the public dataset that they released is particularly useful — especially when we consider what is possible here.
There is, then, a somewhat obvious direction one might wish to investigate: I had thought of whether or not I could use the dataset of reviews to predict whether or not a particular person, based on their reviews, would like a particular place, potentially with some sort of bipartite graph that links restaurants to its reviewers by an edge, and by attempting to figure out some patterns by way of community detection on some attribute of the reviews, users and/or businesses, and using an average of community scores to provide a prediction.
Fortunately for me though, while I was doing some research on the topic, I found that someone had made some interesting graphs with the data, of which I shall speak about.
Creating an appropriate graph
An interesting problem is that working with a dataset of this size, it can be difficult to make a graphical visualization, because you are restricted by the amount of computational resources you have.
Here, the author chooses to use a different algorithm than the one taught in class (i.e., the Girvan-Newman community detection algorithm) — and part of that is likely because the algorithm has a worst-case time complexity of O(nm^2), where n is the number of nodes and m is the number of edges, and in sparse networks, up to O(n^3).
Even with a faster, greedy algorithm (an algorithm that makes choices based on the optimal choice at each step), the author still makes the choice to take a random sample to reduce computational requirements.
The result:
Commentary on the generated graph
- Interestingly, there is a particularly dense component in the bottom right — potentially a large group of similar people. There are also other clusters in the graph, which are likely all smaller communities — perhaps related to their location.
- There are also several “local bridges” across the graph that link the communities
- Some communities have small offshoots — potentially groups of friends that are acquainted with them
Further analysis
This graph alone doesn’t really give us too much detail; so, we will use off-the-shelf data science tools — pandas, numpy, networkx, etc. — and with that we can start looking at the finer details of the communities.
For instance, when we take a random sampling of 50,000 users, we can obtain a graph of the average community size.
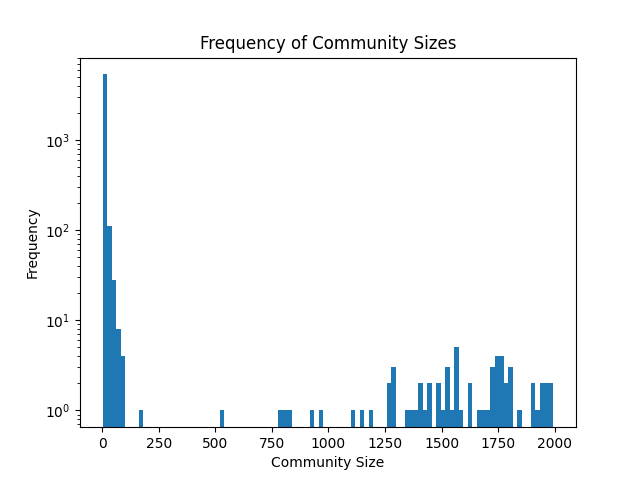
Interestingly, most communities are comprised of ~ 100 members or less. That piques my curiosity — why is that the case?
Smaller groups here could indicate some shared trait — perhaps some sort of likening of a particular group of restaurants.
So, let’s have a closer look at the average number of friends each identified community has.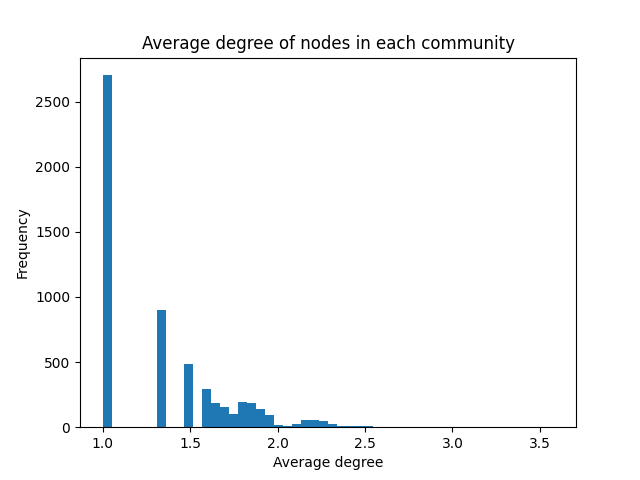
While some only have 1 friend, it appears that the bulk of those remaining have approximately 2 friends.
Maybe then, there is some sort of hierarchy, where small groups of friends have a common trait, perhaps a favourite restaurant or favourite cuisine, and the communities they become a part of end up liking some encompassing trait — like pairs who like Japanese restaurants, and others Chinese, and so on — who all like East-Asian cuisine in general.
Conclusion
Unfortunately, given the computational scale required to compute other interesting details (for instance, I wanted to compute the whether or not community sizes correlated with restaurant categories), I was unable to work through the models I wanted to examine.
That said, this does leave an interesting question — can we:
- Find the strongest factor that determines friendship on the platform
- Use that factor or a group of the strongest factors to find communities of people, then use internal community ratings to produce recommendations
Later on in this course, we do learn about link analysis — so that may be useful in answering this question. Therefore, if nothing else, I hope to be able to revisit this question in my next post — who knows, there are probably other questions to answer here too!
Sources
- http://cs229.stanford.edu/proj2013/SawantPai-YelpFoodRecommendationSystem.pdf
- https://towardsdatascience.com/social-network-analysis-community-detection-2b19e836c76c