Introduction
Out of the many categories of fraud, financial fraud is one which can have many lasting impacts. When financial fraud occurs, it can reduce trust in a company, which in turn would pose a threat to the company’s long-term investments among other effects. This is why financial fraud detection is of the utmost importance, and why there is a big focus on finding ways to increase the efficiency and effectiveness of the detection techniques.
This research article takes a look at using a knowledge graph to increase the accuracy of machine learning models, by allowing them to look at the relationships of Related-Party Transactions (RPTs) between firms rather than looking at the firms as independent individuals.
Analysis
First, let us look at what a knowledge graph is and why it is being used in this article.
A knowledge graph is a collection of nodes, edges and labels, that are created from one or more datasets. The main reason for using this graph in this article is because they want to capture the relationships between firms, which is not really visible in other traditional analysis methods.
Construction of the knowledge graph
In order to construct a knowledge graph, we need information regarding the entities involved (nodes), the relations between the entities (edges), and the attributes of the entities and relations. In this article, they extract this information from the China Stock Market & Accounting Research (CSMAR) Database, looking specifically between the years 2000 and 2019. From the CSMAR, the article had identified companies that had conducted fraud and those that did not.
- For the entities, the article used Named Entity Recognition (NER) to extract the names of listed companies and the related party.
- For the relations, the article looks at the related-party internal/external transactions and uses that to connect the entities.
- From the dataset, the articles finds attributes for both entities and relations.
Then the article conducts knowledge fusion to finish up the construction of the graph. This consists of:
- Linking entities from the knowledge base to the correct entity objects using similarity
- Merging the external knowledge base and handling conflicts between the data layer and schema layer. Again, they use similarity to merge highly similar entities.
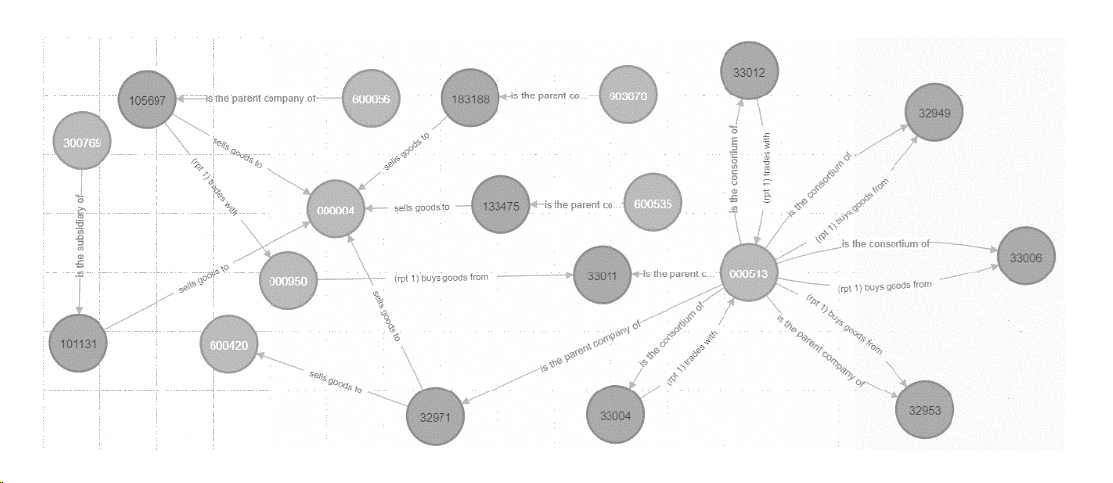
In a traditional analysis method, we could only look at one-to-one relationships, however, as the article states, by calculating the degree of the entity nodes in this knowledge graph, they can extract information about the trade network by looking at the one-to-many and many-to-many relationships.
From looking at these relations, they have extracted the following 7 RPT features that may be associated with fraud:

Then the articles uses these 7 features to make predictions, to verify the performance of these features, using the following machine learning models:
- Linear Regression
- Decision Tree
- Random Forest
- XGBoost
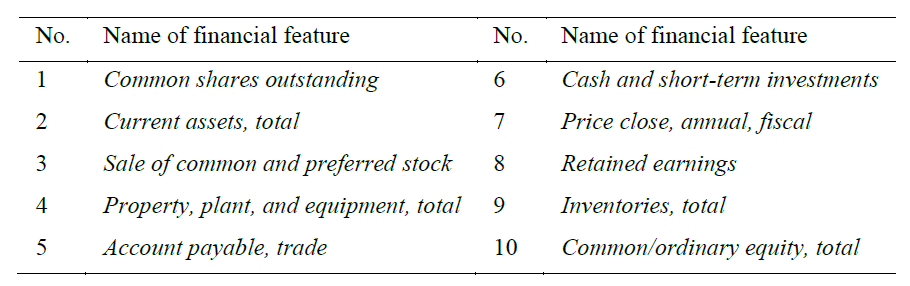
In addition to the 7 RPT features, they also look at top 10 financial (FIN) features used in financial fraud detection. They are as follows:
The article then tests the performance of the machine learning models mentioned previously. In one case they use only the financial features (FIN), and in the other second case, they use a combination of financial features and the 7 RPT features (FIN + RPT). The results of these performances are in the following table, where the bolded numbers represent the best performance:
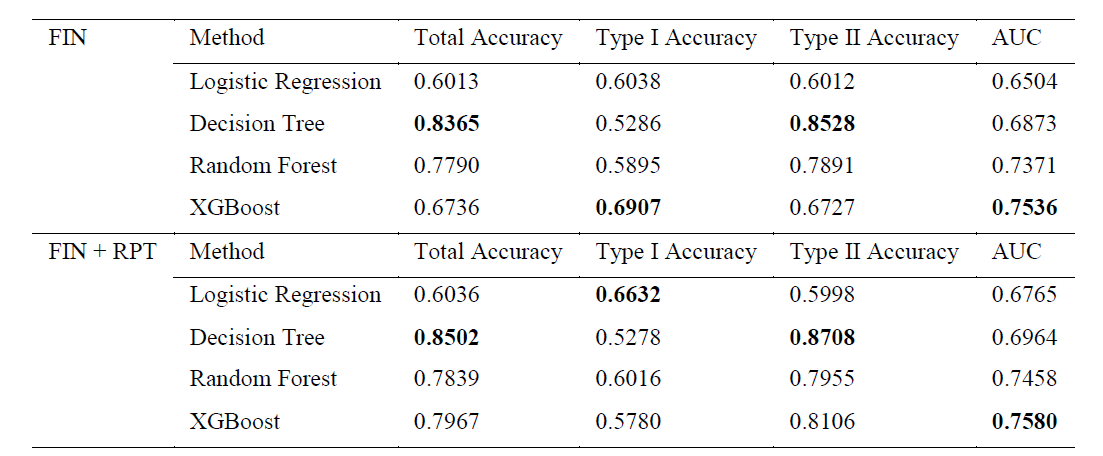
In the above table, we can see that the Type I accuracy is not significantly improved by including the RPT features. In contrast, the Type II accuracy does experience a significant improvement. The article states that misjudging a company for fraud carries a high cost, and so in this case the increase in Type II accuracy is valuable. Hence, they find that including the RPT features in addition to the financial features is an effective method for financial fraud detection.
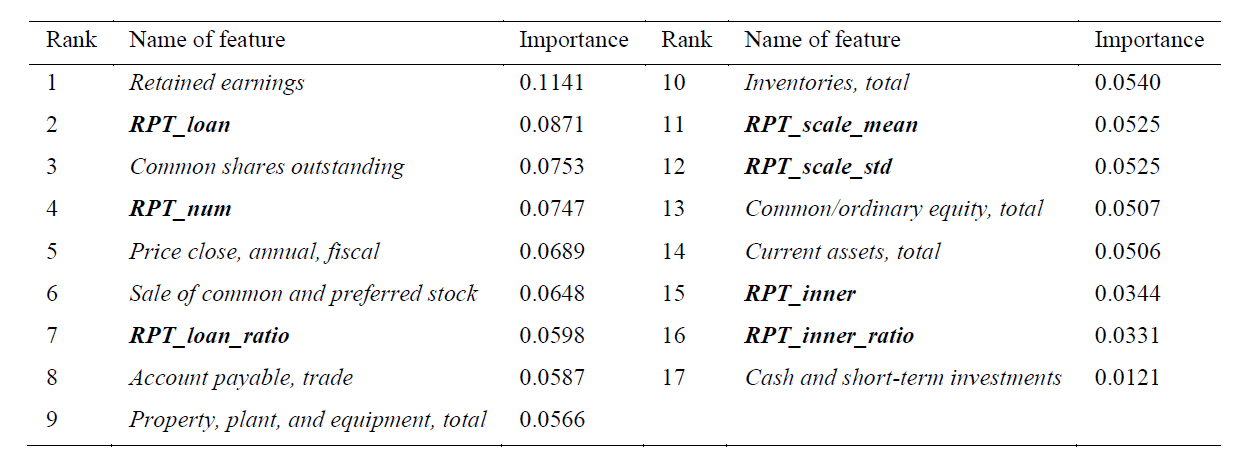
In addition, they also computed the importance of each feature, and found that some of the RPT features were more important than some financial features when trying to detect financial fraud. The results of this are shown in the following table:
Conclusion
This article shows that when discussing financial fraud detection, specifically concerning RPTs, it is important to use knowledge graphs, as opposed to traditional analysis methods. It shows that using the features extracted from a knowledge graph in addition to the top 10 financial features results in more accurate performance of the machine learning models used in financial fraud detection.
References
Mao, X., Sun, H., Zhu, X., & Li, J. (2022, February 3). Financial fraud detection using the related-party transaction knowledge graph. Procedia Computer Science. Retrieved October 21, 2022, from https://www.sciencedirect.com/science/article/pii/S1877050922000928