If your friend was to rave about how much they’re enjoying a certain game, there is a high chance that the next time you’re shopping for a video game, you’d remember your friend’s comments and maybe even be influenced by them to purchase the product they recommended. At the very least, your friend has now made you aware of that product’s existence. Similarly, as you scroll through your social media feeds and see a post from a particular celebrity you follow talking about a certain product, you’ve now been made aware of that product and – oh would you take a look at the likes on that post – so have 100,000 other users just like you. So many trends, ideas and even products are spread because of one person in a network influencing another, who then influences another, and so on like a chain reaction.
The biggest goal of a company’s marketing strategy is to get the word out about a particular product or service. An effective means of doing so would involve having the most impact with the least effort i.e. maximizing the number of people who are aware of a certain product by setting off the chain reaction at a subset that only includes the “best and most influential” users they can reach out to. This is the basic idea behind every social media campaign – working to solve the Influencer Maximization (IM) problem. The goal of this maximization problem is to find a small subset of nodes that can maximize the spread of influence over a social network graph. Applying such a strategy is called Viral Marketing (“word-of-mouth” advertising).
A company that employs this strategy would select a handful of influential individuals and offer discounted products and services to them in the hopes that they would be recursively recommended, thereby starting a cascading effect in which the product goes viral and reaches a large number of people, as each node influences its neighbours/friends.
The IM problem can be solved through two steps: first, we create a diffusion model that describes how influence is spread over an Online Social Network (OSN) graph. Then, we apply a maximization algorithm that seeks out the set of nodes in the graph such that activating that particular node would maximize diffusion across the graph. The activation of a node is equivalent to bringing awareness of a product to a person.
In general, an OSN is modeled as a graph database that is an undirected edge-labeled graph. For example, take the case of YELP. YELP is an Online Social Network that allows users to foster friendly relationships and submit reviews on business objects (like restaurants). We can represent YELP as a graph in which the vertices set is made up of Users and Business Objects, while a friendship between two Users or a review between a User and Business Object counts as an edge of the graph. A social path is a particular edge-labeled path. In the image below, P1 = {vinni, friendship, giank} and P2 = {vinni, review, gamberorosso, review, giank} are two social paths connecting two Users.
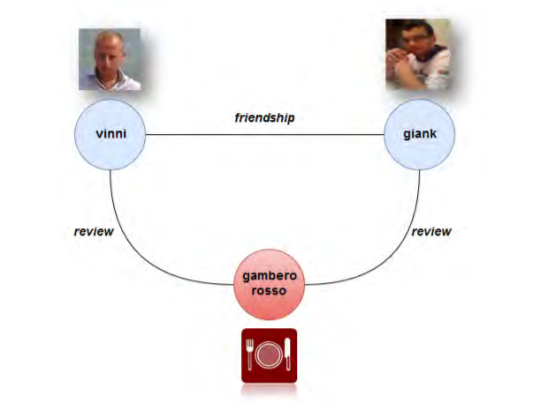
We can then derive the most relevant social paths by checking whether the elements of a particular social path match a set of conditions defined on the attributes of the nodes and edges belonging to that path. For example, in our above image, we can see how P1 and P2 are different ways by which a User can “influence” another User. The relevant social path is expressed by regular path queries on a graph database. A regular path query (RPQ) over a set of edge labels is the regular expression over those edge labels. By combining regular path queries with the set of conditions, we can effectively extract the relevant social paths. For example, by performing an RPQ that returns the set of Users who have reviewed the same business object, and attaching the conditions that the attribute “mood” of the review is the same and the attribute “timestamp” of the first User’s review is less than that of the second User, we can get the most relevant social path in which User 2 has given a similar review right after User 1.
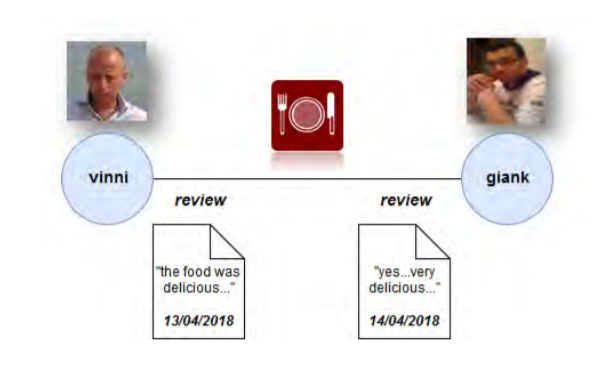
Using this information, we can then build an Influence Graph, in which each edge is assigned an influence probability. This technique employs the Combinatorial Multi-Armed Bandit (CMAB) framework in which we estimate the influence probabilities recursively using an Influencer Maximization algorithm that aims to reduce the regret (difference between the optimal solution and current influence probability). It does so through an exploration-exploitation trade-off technique (essentially, a coin flip). If the metaphorical coin lands on exploitation, a greedy strategy is used, and if it lands on exploration, randomization is used. Thus, we improve our knowledge each time to minimize the regret in the next step, ultimately obtaining the correct influence probability values that can help us determine who the most influential users are.
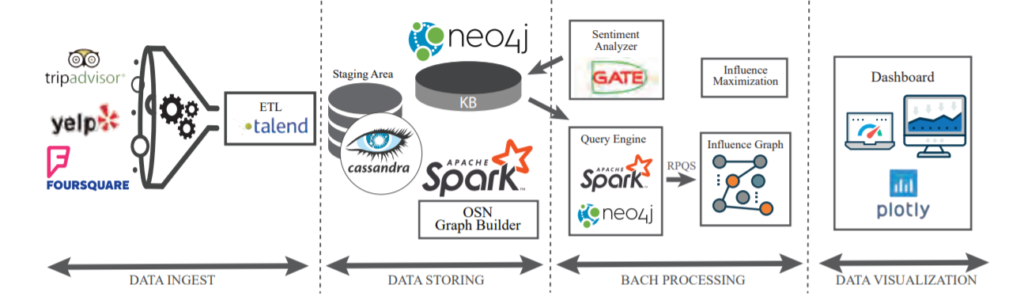
A rough overview of the entire process is outlined below:
i. Data Ingestion – data extracted from OSNs like YELP etc.
ii. Data Storing – data is cleaned and stored in a particular format containing certain attributes (like “mood”, “timestamp” etc. in the case of YELP)
iii. Batch Computation – RPQs are used to help build the Influence Graph on which the Influencer Maximization procedure is applied
iv. Data Visualization – results such as the Influence Graph and the most influential users are presented in a visual manner
So the next time you see your favourite Youtuber sponsoring a product or playing a game that they were sent an early access code of, try to think about all the behind-the-scenes that went into choosing that particular person to spread the word about the product and ask yourself if you’re now more likely to buy it because you saw them using it. If your answer is yes, well… you’ve been hit by, you’ve been struck by, viral marketing.
Source: Cuzzocrea, A., Moscato, V., Picariello, A., & Sperlí, G. (2019). Querying and Learning OSN Graphs for Advanced Viral Marketing Applications. Proceedings of the 2019 3rd International Conference on Cloud and Big Data Computing – ICCBDC 2019, 117–121. https://doi.org/10.1145/3358505.3358525
2 replies on “Viral Marketing: Maximize Influence, Maximize Profit”
This explains why so many companies chase influencers to market their products. In fact, it would be a good idea to reach out to influencers who are weakly connected or don’t know each other (Similar to how our acquaintances are more likely to find a job for us rather than a friend)
Exactly! If they’re weakly connected, then their audience or reach would extend to two networks that would have minimal overlap so the company can get their product out to more diverse and varied groups of people.