Communities. When most people think about them, we usually think of a group of people that have strong ties to one another. They trust each other and, more importantly, are willing to cooperate with one another to achieve a goal. But being the evil little gremlin I am, I wondered to myself, how strong are these communities actually? What would it take to completely demolish a community’s willingness to cooperate with one another? And then I stumbled upon an article titled “Information Cascades and the Collapse of Cooperation” by Tang et al., I was instantly intrigued and felt the need to write about it. I wanted to gain insight into community dynamics and see empirical evaluations of the process of being a newcomer to a community. I also wanted to witness the effects bad actors in a community can have in a quantified manner. I felt that such information could help me grasp the importance of various mechanisms of communities such as moderators, especially in the realm of online forums.
I’ll quickly give a rundown of Yang et al.’s study. Given an underlying social network, each node is classified either as a cooperator or a defector. As time passes, a new node is introduced, and they connect to a node in the network, which they call a “role-model”. Ideally new nodes would want to connect to cooperators and avoid defectors. When the new node is making their decision, they have access to public and private information. The public information is simply the degree of nodes in the network and the private information is a sample taken from one of two Gaussian distributions, one for cooperators and another for defectors.
I’ll quickly describe some important variables used in the study. Cooperators distribute a benefit of b value to its neighbours for a cost c. There is also a variable denoted as δ (the “selection strength”), which is basically the degree to which a node will consider its payoff when choosing to connect to a role-model. The higher δ, the more likely it will connect to role-models that provide a larger payoff. p is a weight between 0 and 1 which defines how heavily public information should be considered when deciding whether to connect to a role-model; q is defined similarly for private information. Finally, there is the notion of P-cascades and N-cascades which are information cascades that form when there is a conflict between private and public information. P-cascades are cascades that are created when the private information of newcomers indicate they should connect to a role model, but instead they follow public information and don’t connect. Similarly, N-cascades are cascades where private information of newcomers indicate they shouldn’t connect to a role model, but instead follow public information and connect.
In terms of content relating to CSCC46, the study tackles the concepts of game theory and information cascades. Yang et al. utilized game theory (specifically evolutionary game theory) by treating connections between nodes as a game where the payoffs are based on a pre-defined benefit and cost variable.
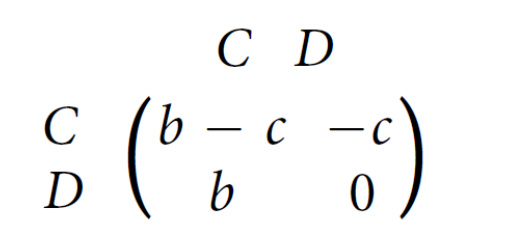
Information cascades are a concept in CSCC46 that this study directly addresses when it comes to the role-models newcomers choose. If public and private information about whether a node should connect to a role-model conflict, newcomers may make the wrong decision when choosing to connect/reject a node. If a series of wrong decisions are made, this can cause successive newcomers to simply follow the crowd and make the same mistake, leading to a P-cascade or N-cascade.
What I found interesting about this study is how they allowed public and private information to be weighed differently. This sort of mimics how people in the real world might behave in this kind of scenario. You may have people who are more comfortable going along with the crowd, thus they will value public information more heavily. Likewise, someone who is more independent may have more confidence in their own private information and thus will weigh it more heavily. On a related note, in the study, Yang et al. discovered that public information had significant effects on the underlying social network, even if it was in limited amounts.
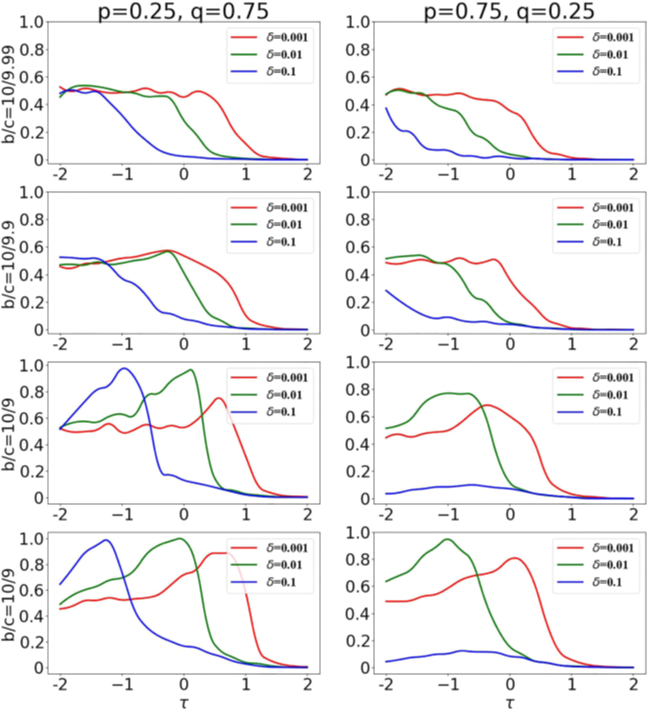
Notice in Figure 2, private info generally has a high degree of cooperation which lasts for higher decision thresholds, as shown by the left side. Meanwhile on the right side, cooperation values were lower when public information was being considered more. These findings could be an approximate answer to the question I proposed at the beginning of this blog. If a group of individuals were to distort public information, even just little bit, it could take a serious toll on how communities cooperate and function as a whole. Subsequently, this provides a basis for why community moderators seem so important. They can control community dissidents and prevent public information from being absurdly polluted.
While this study was only an approximation, it gives a rough idea why cooperation is so fragile within communities. If others were to build upon this research and perhaps obtain real-world data on this subject, a mitigating factor can be discovered for the reasons behind such fragility. Not only would this make communities more resilient to collapses in cooperation, but it could also point towards a solution the actual cause of these collapses, stopping them once and for all.
References
Yang, G., Csikász-Nagy, A., Waites, W. et al. Information Cascades and the Collapse of Cooperation. Sci Rep 10, 8004 (2020). https://doi.org/10.1038/s41598-020-64800-z