In class, we learned about the Six Degrees of Separation. I find it interesting how I can be linked to another person on the planet with about six steps. As I begin to take in the information, I began to wonder if this concept is applicable to other things beside social connections, and this is where I got the idea of cybersecurity.
As a result, I have come across some interesting articles that talk about the connectivity and the issues that this might bring (links below). If we as people are that connected together, what does that tell us about our security online? Does this pose any problems? Through the integration of technology in our lives, a lot of our tasks are increasingly being done online. This connectivity can be convenient, but it can also be a risk.
In one of the articles, one thing I found interesting was where they describe a scenario. The scenario is, if someone connects to a network (for example at a coffee shop), then this individual’s device is one degree separated from all the other users on the same network. Since many people use their devices (smartphones) for work, that means that this individual is two degrees away from the connected devices of other people, in their work, homes and more. If someone were to plant malware on the devices in the network, it can spread really easily. Relating to the six degrees of separation and how one person can be connected to anyone in the world in about 6 steps, this means that it can spread globally very quickly, if the connected devices are unprotected. Reaching a specific device in the world may not be the same as six steps for people, but it may not require a large number of steps either, depending on how the malware is designed.
Another interesting point involves the risks that impact supply chains. In the supply chain, each part is connected and so if one part of the supply chain were to be attacked, the entire chain is affected. They have included some example risk scenarios to illustrate what could happen, and one of them is a data breach.
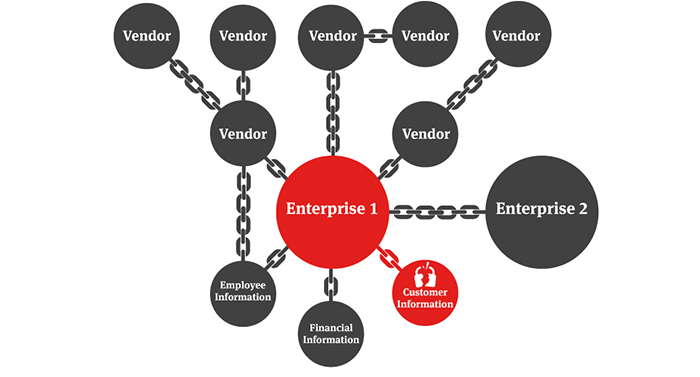
The above diagram illustrates a data breach that has happened to Target back in 2013. One of their suppliers was compromised and from that point, the attackers were able to target Target’s internal network.
After reading through this case, and seeing how connected systems can be vulnerable, this also makes me wonder how vulnerable we are. We are connected to many people around the world through our social medias and connections online. Like the example above, if someone wanted to infiltrate Person A’s system, they don’t have to target them directly, but they can target someone else connected to Person A and then use that connection to get to Person A. From the Six Degrees of Separation, that could mean that the attackers could find a lot of entry points (anyone in the world is separated by around 6 steps) and eventually, they will reach Person A. It is important to secure our devices, so malware does not spread that easily, and allow less entry points from other people.
Links:
https://www.securityroundtable.org/6-degrees-of-iot-the-kevin-bacon-theory-of-networking/