In lecture, I found the bow tie structure of the web very interesting to visualize. While thinking about how the structure works, a thought popped up to my head about the dark web. From my understanding, the dark web is the part of the web that is not indexed by search engines and can only be accessed through special software. The random thought and curiosity of the web’s structure, led me to question what the structure of the dark web is like.
I wondered if the same bowtie structure holds for the dark web as well, so I did a little bit of digging and came across an paper where they try to answer that question. They first did some crawling through the dark web pages, which they defined as the websites in the onionweb, domains in the “.onion” pseudo-top-level-domain. Through this process, they have made many interesting observations. One observation in particular, is that the structure of the dark web is very different from that of the World Wide Web. In the chart below, it shows the distribution of the websites in their respective groups of the bow-tie structure.
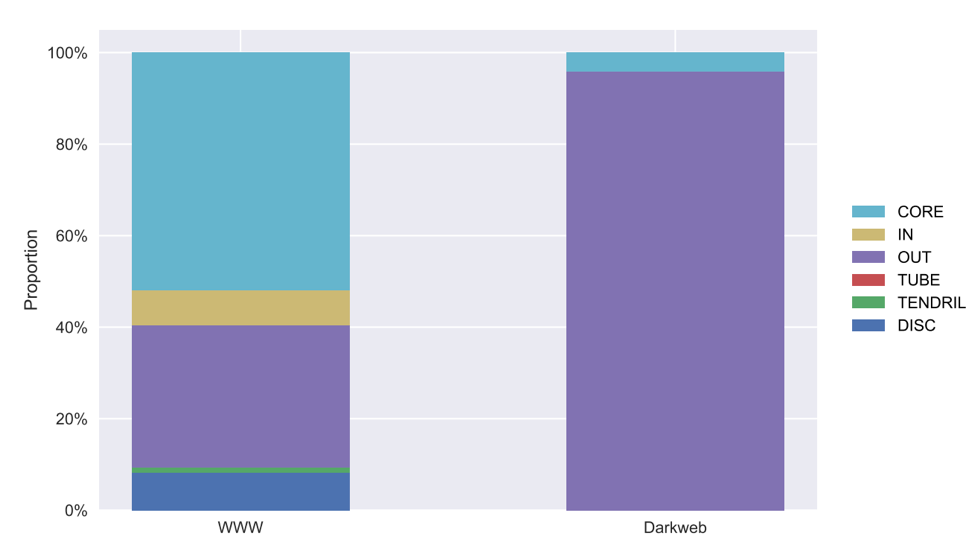
It is very interesting to see that most of the websites fall under the OUT group, a very small percentage in the CORE group (the group also called the Giant SCC). None of the websites are in the IN, Tube, tendrils, or disconnected groups. One interesting fact they have observed, is that 87% of the websites do not link to another website.
Based on this information, the dark web does not seem to take on the bow-tie structure. The article did offer some suggestions to why this may be the case, but I have a few ideas as well. Based on my understanding, access to the onionweb is designed with anonymity in mind. To access the network requires the Tor browser which takes extra steps to anonymize the users compared to other browsers we may be familiar with. Also, since the dark web requires more steps in order to access, compared to the World Wide Web, I would make the assumption that the content may be more secretive. So the content may not be designed for anyone to access but only for a select few. Having many links from other web pages may make them easier to access. No entry points would imply that there would be no websites in the IN group. However, the urls in the onionweb do not have a readable address but is a randomly generated 16 character. It would be very difficult to remember them and maybe there is a list where they can be accessed from. This might explain the presence of the Giant SCC group (CORE in the chart) and why the websites are not all disconnected from each other.
The paper goes into more detail of how they crawled through the websites and other interesting observations, which I have not gone into detail in this post, but it can be accessed through the link below: